

 Apache Kafka builds real-time streaming data pipelines. What this means is that; using apache Kafka you can move data from one system to another system or from multiple source systems to multiple target systems. This is a very common use case in big data applications.
Apache Kafka builds real-time streaming data pipelines. What this means is that; using apache Kafka you can move data from one system to another system or from multiple source systems to multiple target systems. This is a very common use case in big data applications.
As a data engineer, you must know about big data, Apache Hadoop, Apache Sqoop, Spark and Apache Kafka at the minimum. These sets of tools in your resume will get a decent job as a big data engineer.
If you want to raise the bar by few notches up, then we highly recommend you to learn about ELK stack. An ELK stack stands for ElasticSearch, LogStash and Kibana. There are 3 tools in one and if you know how to integrate them with apache hadoop applications such as HDFS, Hive, Pig and MapReduce, you are in high demand by companies all around the world. Here’s an interesting course that can help you learn ELK stack in just 6 hours.

In this post, we will discuss about Apache Kafka architecture and its internal components in detail.
Anatomy of Kafka Architecture
Apache Kafka is made up of various components and each one of it has a specific function to perform. We will now cover most important components of Apache Kafka that you must know about. So, let us start with Kafka Brokers.
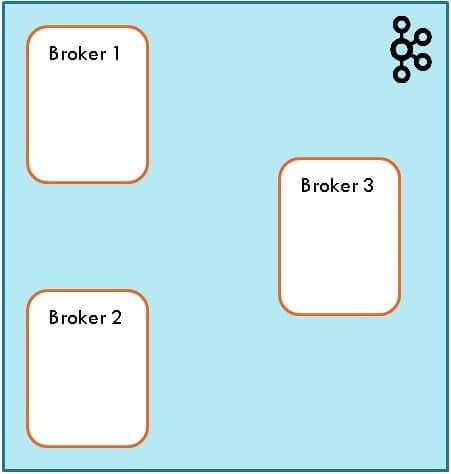
Apache Kafka Brokers
- A Kafka cluster consists of one or more servers called brokers
- Each broker is identified by its unique ID
- A broker may have one or more topics
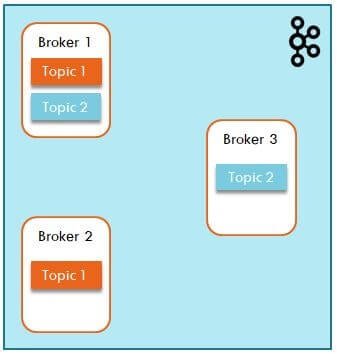
Apache Kafka Topic
- A Kafka topic is a like a queue where data is coming from one end and read from another end
- Topic is the basic storage unit inside Kafka
- A topic must have a unique name
- Once the data is written to a topic it can not be changed
- An update can be sent as a new message to the topic but previously sent message is immutable
- Messages are stored in the order in which they are sent inside a topic partition
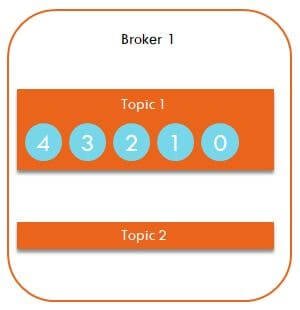
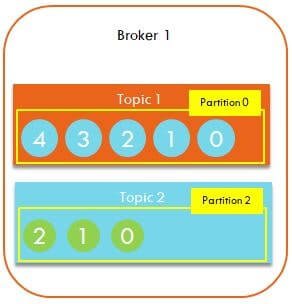
This is how data messages are stored inside a Kafka topic. Each message is queued up as show below. Topic 1 has 5 messages starting from 0 to 4.
Kafka Partitions
- Partition holds a part of the data
- A Kafka topic can have N number of partitions
- The minimum number of partitions is 1
- A partition is similar concept as the partitioning of data in a SQL or Hive table. Similarly a topic’s data is split into partitions
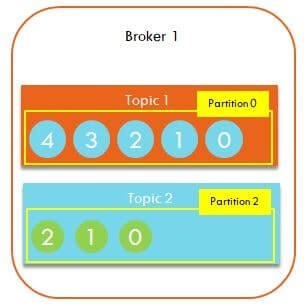
For instance, say a topic has 2 partitions inside it:-
- It means that data will be randomly sent to either of 2 partitions.
- If incoming data has a key defined, then same key data will always be sent to same partition.
- More partitions mean more parallelism.
Offsets
- Each message in a partition gets a unique id called offset
- The subsequent messages in a partition will have incremental offset ids
- Within a partition the offset Ids are unique but across partitions they are not unique
- Offset ids are used by Kafka to keep track of which messages are read by consumers
Topic Replication in Kafka
- Replication provides data protection against server failures. If a server (broker) fails, data can be used from another broker
- Topics are replicated across different brokers to provide fault tolerance.
- Default replication is 1 which means data may be lost in case broker is down.
- Ideal replication is 3 which provides good enough protection against data loss.
- The copy of a topic is always stored on different brokers. No broker will have master & replica of the same topic partition stored simultaneously
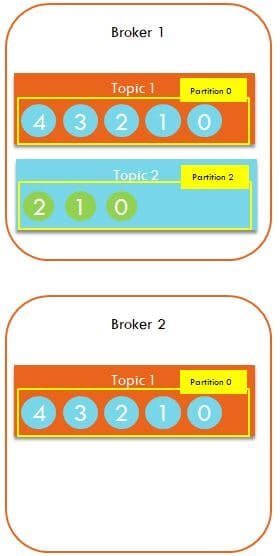
As you see, Broker 1 has topic 1 and Broker 2 also has a copy of topic 1.
Partition Leader
- Since data is replicated across the Kafka cluster of brokers, it is important to have one of the partition elected as the master aka leader
- Only a leader broker will be responsible to receive new data for specific partition
- From leader, all replicated nodes will synchronize the data
- Leader will be responsible to respond to all data queries
- LEADER = MASTER of a Partition
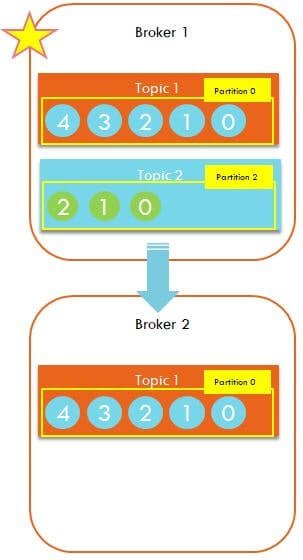
Broker 1 is assigned as the leader for Topic-1. Broker 2 has the replica of topic-1 and it syncs it with leader broker.
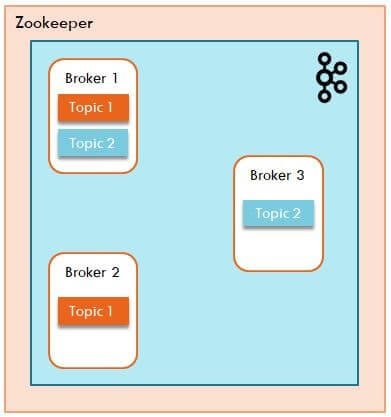
Zookeeper
- Zookeeper is the server manager which keeps track of which broker is down so it can start a new broker in its place
- Apache Zookeeper also elects the leaders for topic partitions
- If a leader is down, then zookeeper assigns one of its replica as the new leader and from there onwards, all traffic start flowing to that new leader
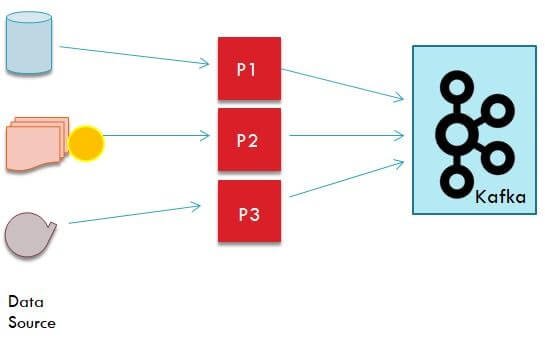
Kafka Producers
- A Producer is responsible to send data to Kafka cluster
- Producer may be connected to a data source and reading data from it
- Producer only specifies the topic to which data needs to be sent to. Kafka internally sends the data to the leader node of that topic’s partition
- You can configure producer to wait for the acknowledgement that data is:
- successfully processed by all nodes (ack = all)
- received by leader only (ack = 1)
- no acknowledgement (ack = 0)
Yellow circle is one single message unit.
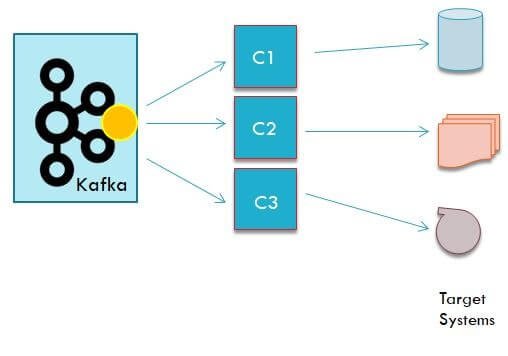
Kafka Consumer
- A consumer is responsible to read data from Kafka cluster & send to target systems
- Consumer only has to provide name of topic from where to read the data, Kafka will ensure consumer reads data from leader of the partition for that topic
- The consumer reads the data in the order using offset id.
- Kafka internally tracks which offset ids are read by a consumer so same message isn’t read twice (in a topic = __consumer_offsets)
- Multiple consumers can be grouped together in which case each consumer will read from different partition
- If there are more consumers than number of partitions, then some of the consumers will be idle
Related Posts
BECOME APACHE KAFKA GURU – ZERO TO HERO IN MINUTES
ENROLL TODAY & GET 90% OFF

- Mastering Apache Kafka Architecture: A Comprehensive Tutorial for Data Engineers and Developers
- Spark Streaming with Kafka
Consumer Commits
At most once
- As soon as a message is received by a consumer, it is committed in Kafka
- Kafka will not allow consumer to read that same message again from the partition
- In most cases this mode should be fine but if a consumer goes down or fails in between, then the last message read will be lost and will be missed in processing
When to use this –
- Use this configuration in cases when some data loss is OKAY and won’t break the application or business use case
At least once
- As soon as a message is processed by consumer it is marked as committed
- Please note in this case we are saying as soon as a message is processed not received as in the previous case
- With this configuration, if consumer fails to process a message, or goes down before message could be processed successfully, it can read it again from Kafka and retry
When to use this –
- Use this configuration in cases when processing duplicate messages won’t break the application or business use case
Exactly once
- In this case, even if producer sends a message twice it should only be added to Kafka topic only once
- This mode avoids duplicate messages
- To enable this feature on producer side, use enable.idempotence=true
- Behind the scene, each batch of messages sent to Kafka will have a sequence number which the broker uses to avoid duplicates. On consumer side, client application must not break if same message is processed twice. Kafka stream API has this feature in-built which can be enabled as: processing.guarantee=exactly_once
- This makes Kafka stream to send and process messages exactly once
When to use this –
- In mission critical applications where each message must be processed and that too only once
We hope you liked this post. Please don’t forget to share it on your LinkedIn profile.
[…] Anatomy of Kafka Architecture […]
[…] Anatomy of Kafka Architecture […]