


Are you looking to avoid small files problem in Hadoop? Read below to learn exactly where to look for and how to avoid small files problem in Hadoop.
Hadoop is a software framework to store and process huge amounts of data in distributed manner. Hadoop can handle 10s of petabytes of data in volume. Just to give an idea here’s what 1 petabyte looks like:
1 PB = 1000000000000000B = 1015 bytes = 1000 terabytes.
As mentioned earlier Hadoop can handle 10s of petabytes or may be even more. This is one of the reason why Hadoop is the BEST Big data Platform today. Just to be clear the problem that we are going to discuss here; isn’t with the volume of the data that Hadoop can store but number of files that it has to manage.
Related post:
Why Large number of files on Hadoop is a problem and how to fix it?
Often these files are small in size that is few 100 MB or even less which is not good at all especially for a system like Hadoop that is designed to hold large amounts of data. To understand the root problem, let’s see how a data file is stored in Hadoop.
Distributed Storage on Hadoop
When a file is moved to hadoop for storage, Hadoop internally divides that file into something called Data Blocks. Depending upon how the Hadoop server is configured, each data block size may be set to 128MB or 256MB.
What this means is that, say we have a 1000MB file to be stored on Hadoop. Internally this file would be split into 1000/128 = ~8 data blocks or 1000/256 = ~4 data blocks. By the way, if each file is 1000MB in size, then 256MB block size will provide much optimized storage than 128MB file. But that is far from reality. Moreover, it’s not just data files that Hadoop stores. It stores all different other files too such as; container log files, temporary files, intermediate files, etc. The impact of these files on overall Hadoop performance is discussed here. I recommend you to read it too.
Now you will ask, Ok so we have lots of files. Why that is a problem? To answer this, we need to understand the architecture of Hadoop and its components. Here’s a quick walk-through over Hadoop’s architecture.
Want to learn more about hadoop, we recommend you to check this out.
Quick side note, here is a list of related posts that I recommend:
- The Best Data Processing Architectures: Lambda vs Kappa – Confused which architecture to use while designing big data applications. This article can help.
- 6 Reasons Why Hadoop is THE Best Choice for Big Data Applications – This article explains why Hadoop is the leader in the market and will be one for long long time.
- How to Quickly Setup Apache Hadoop on Windows PC – step by step instructions on how to getting started with Hadoop
- How to setup Apache Hadoop Cluster on a Mac or Linux Computer – step by step instructions on how to get started with apache Hadoop on a Macbook or Linux machine.
- Learn ElasticSearch and Build Data Pipelines – This is actually an intro to a very comprehensive course on integrating Hadoop with ElasticSearch. This is one of key skills for advancing your data engineering career.
- Why Large number of files on Hadoop is a problem and how to fix it? – find out how so many files are created in hadoop which eventually hit system’s performance.
This is how a High end Server looks like for a high-end hadoop cluster. It costs big bucks. Imagine a data center with thousands of such nodes. Typical hadoop clusters have small and cheaper hardware but industry is shifting towards high-end nodes to boost overall network speeds.
Components of Hadoop
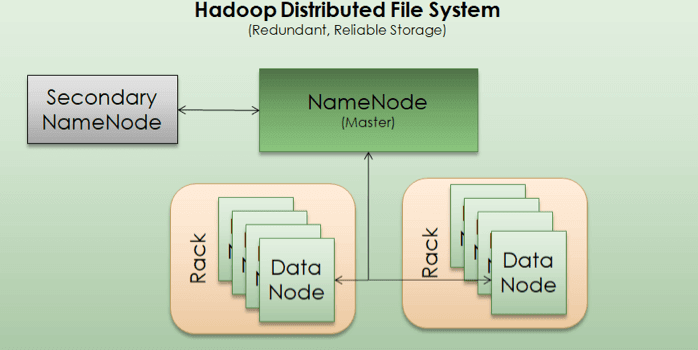
NameNode
As we learned above that files are stored in form of blocks on disk. So, there’s a need for a catalog system which can locate each block of a file across distributed machines. In addition, Hadoop also replicates each block three times so it has 3 different data nodes where copy of same block will be saved in.
To manage each file and location of its data blocks, a machine is designated as NameNode. It is same kind of machine as data node but with limited storage and memory as its prime job is to maintain an index of data blocks and not the actual data. It is very important to avoid small files problem in Hadoop for proper functioning of NameNode.
NameNode does not store actual data as such but only metadata about the files and its blocks. So if a NameNode is down or crashed, system won’t be able to access data blocks and whole setup will be jeopardized. Right. This is why to avoid having NameNode as a single point of failure; there’s a backup of NameNode also. This is called Secondary NameNode. In case a NameNode fails, Secondary NameNode will take over the cluster. This is done pretty autonomously by Hadoop itself.
Secondary NameNode
As explained in NameNode section, secondary NameNode is the backup of Primary NameNode and is used to avoid single point of failure in the system.
Data Node
Data node is where the actual data blocks are stored. Each block can be around 128MB or 256MB depending upon how a cluster is configured. The Data nodes are responsible for serving read/write requests from client systems, or block creation/deletion/rename requests from NameNode. In order to avoid loss of a data block, they are usually replicated on other Data nodes.

By default, Hadoop recommends a replication level of 3 meaning a data block will have at least 2 more copies of itself. As Data Nodes are small and consists of bare minimum components unlike a regular laptop or desktop, they are stored in stacks on racks. A rack may hold 10-30 data nodes in a typical setup and an organization may have tens of hundreds of racks in its data center. The default configuration is to save first copy of a block in a data node stored on the same rack as actual data block, while second copy is stored in a different rack to deal with rack level failures. This approach provides well enough speed as well as fault tolerance against data loss in most of the cases.
Here are our favorite books that we recommend you to learn more about Hadoop.


How do we avoid small files in Hadoop then?
Well there are multiple things that need to be done in order to avoid creation of small files on Hadoop at first place itself. Here are some:
-
Ensure source sends larger files
If your Hadoop implementation is receiving data from external sources in form of files, then ensure that sender system generates large-sized files. For instance if a data source is sending 100MB file every hour to your system, you can ask them to send all files at end of day in single large file of 2.4GB or 2400MB. In most cases, this approach works as long as ingestion of this data can be delayed and isn’t really required in real-time.
For real-time scenarios, there will be a need to create some kind of custom processes to combine smaller files as soon as ingestion is complete and analytics are generated for client applications. So, ensure during designing of your Hadoop applications, that source systems send larger files at least few Gigs in size. By following this simple design rule, you can avoid small files problem in Hadoop greatly. Next bullet item explains how this can be done.
-
Use Hive Concatenate Functionality
This approach will be helpful when data is stored in Hadoop and hive tables are built over it. Basically, Apache Hive provides a command to merge small files into a larger file inside a partition. Here’s how that command looks like:
ALTER TABLE table_name [PARTITION (partition_key = 'partition_value' [, ...])] CONCATENATE;
Remember this works only if data files are stored in RC or ORC formats. As of today Hive Concatenate functionality doesn’t support Text files merging. Moreover files will be merged inside a partition only not across partitions. In other words, if there’s a table having daily partition with each partition holding about 10-20 small files, then you can use this command to merge those 10-20 files to say 3-5 files. This will result in reduction of file count inside a partition. This approach works best if you have partitions with large number of files and large overall data size per partition.
With this approach, we can avoid small files problem in Hadoop in case of data is already ingested into the cluster.
Related content:
How to find bad partitions in a huge HIVE table – Before you use alter table command to concatenate files in Hive, I highly recommend you to read this article.
-
Configure auto purge job
Often data is loaded and then forgotten. Ensure that you have good retention policies in place. What this means is that; if data that you are storing has no meaning after 30 days, 1 year or 5 years, then make sure that it is cleaned after it’s not needed. This will recover huge amounts of storage and helps in limiting number of files in Hadoop to acceptable levels.
For this, you can set up CRON jobs in Linux or use some work flow management tool such as Tivoli WorkFlow System or Oozie. These purge jobs should run on recurring basis and check if certain data is old enough to be deleted. This simple job can save lots of cost for a company as well and avoid small files problem in Hadoop for long time.
-
Clean Log files
Hadoop’s YARN allocates resources to processes that run on Hadoop Cluster. For each process, it generates container logs that are also stored in Hadoop nodes by default. It is important that these log files are cleaned after they are not necessary. Having a 2 weeks of retention for such logs is more than sufficient in most cases. You can read more about such logs files in here. Often this step is missed by administrator teams while designing the system. It is a key to avoid small files problem in Hadoop.
-
Clean Temporary files
The processes running on Hadoop creates lots of intermediate or temporary files during their execution. If a process fails in between, which by the way happens quite often in Hadoop, these intermediate files won’t be cleaned. For instance Hive queries create intermediate files as .hive-staging-xxx which should be cleaned after query is successfully finished. If process execution is interrupted for any reason, you will end up with lots of .hive-staging-xxx files besides data files. To counter this particular problem, we can change global settings to store .hive-staging files to say /tmp location. For this, update hive-site.xml and add following property:
<property>
<name>hive.exec.stagingdir</name>
<value>${hive.exec.scratchdir}/${user.name}/.staging</value>
<description>
You may need to manually create and/or set appropriate permissions on
the parent directories ahead of the time.
</description>
</property>
In Hive >= 0.14, set to ${hive.exec.scratchdir}/${user.name}/.staging
In Hive < 0.14, set to ${hive.exec.scratchdir}/.staging
These files are anyway intermediate files which can be regenerated by re-running the Hive queries again. But still we recommend you to carefully imagine your case before applying this step. Also, ensure that the performance of the system isn’t impacted after this.
Many of our students have raised their income just by doing this 6 hours professional training course. We highly recommend you to take this course to succeed as an expert big data developer.
We hope that this post proves immensely helpful to you and your organization. In this article we have featured How to avoid small files problem in Hadoop? We believe you will implement same good practices at your organization as well.
If you liked this How to avoid small files problem in Hadoop? article, then do share it with your colleagues and friends. Do you have any questions or suggestions for us, please leave it in the comments section below.
[…] Pingback: How to avoid small files problem in Hadoop and fix it? […]
[…] Address the notorious small files problem (see also here and here) – Table partitioning – Denormalise (table joins are usually one of the most […]
[…] How to avoid small files problem in Hadoop – This post provides steps to avoid small files problem in Hadoop. It is a must read for anyone working on Hadoop. […]