

 If you have checked our post on How to Quickly Setup Apache Hadoop on Windows PC, then you will find in this post that its comparatively easier to install Apache Hadoop cluster on a MacBook or Linux computer. In this post, we will provide you step by step instructions on How to setup Apache Hadoop cluster on a Mac or Linux Machine. Before we proceed we need to understand various installation modes that Hadoop offers natively. Here’s a quick recap of what we also covered in How to Quickly Setup Apache Hadoop on Windows PC
If you have checked our post on How to Quickly Setup Apache Hadoop on Windows PC, then you will find in this post that its comparatively easier to install Apache Hadoop cluster on a MacBook or Linux computer. In this post, we will provide you step by step instructions on How to setup Apache Hadoop cluster on a Mac or Linux Machine. Before we proceed we need to understand various installation modes that Hadoop offers natively. Here’s a quick recap of what we also covered in How to Quickly Setup Apache Hadoop on Windows PC
Hadoop is designed to work on a cluster(read as ‘multiple’) of computers (called machines or nodes) but its engineers have done excellent job in making it run on a single machine in much the same way as it would do on a cluster of machines.
In a nutshell, there are three installation modes supported by Hadoop as of today and they are:
Local (Standalone) mode
The Local or standalone mode is useful for debugging purposes. Basically in this mode; Hadoop is configured to run in a non-distributed manner as a Single Java process that will be running on a computer.
In other words, it will be like any application such as Microsoft Office, internet browser, etc that you run on your computer. This is the bare minimum setup that Hadoop offers and is mainly used for learning and debugging purposes before real applications are moved to large network of machines.
Here’s an ultimate Macbook Pro in our opinion


Pseudo Distributed mode
Pseudo distributed is the next mode of installation provided by Hadoop. It is similar to Local/Standalone installation mode in the sense that Hadoop will still be running on the single machine but there will be Multiple Java processes or JVMs (java virtual machines) that will be invoked when hadoop processes starts.
In Local mode, everything is running under single Java process but in Pseudo Distributed mode, multiple Java processes will be running one each for NameNode, Resource Manager, Data nodes etc. This installation mode is most near production like experience that you can get while still running hadoop on a single machine.In this post, we will show you step by step how to set up Apache Hadoop Cluster on a Mac or Linux Machine in Pseudo Distributed mode.
Fully Distributed mode
This is the mode used for production like environments consisting of tens of thousands of machines connected together to form a large network of machines or a cluster. This mode maximizes the use of Hadoop’s underlying features such as distributed data storage and distributed processing. If your organization is into big data technologies, then most likely their setup will be in fully distributed mode.
Next, we will cover the steps needed to install Apache Hadoop on a personal computer (laptop or desktop) with Mac OS X. Please note these same steps can be applied to a Linux or Unix machine for example centOS or RedHat Linux, etc.
Quick side note, here is a list of related posts that we recommend you to check:
- 6 Reasons Why Hadoop is THE Best Choice for Big Data Applications – This article explains why Hadoop is the leader in the market and will be one for long long time.
- Integrate ElasticSearch with Hadoop Technologies – This is actually an intro to a very comprehensive course on integrating Hadoop with ElasticSearch. This is one of the key skills for advancing your data engineering career today.
- How to Quickly Setup Apache Hadoop on Windows PC – If you are a windows PC user and landed on this page, then we have detailed instructions on how to install Apache Hadoop on Windows PC in this post.
- Installing Spark – Scala – SBT (S3) on Windows PC – If you want to learn Spark then this article will help you get started with it.
Alright, now let’s roll up our sleeves and get started installing Apache Hadoop on Mac.
Pre-requisites
You may need to be logged in as the root user in order to install these.
HOMEBREW
Homebrew is a package manager for Mac and Linux operating systems. It makes it very easy to install utilities and other tools on your computer without worrying about individual dependencies.
Often you will need dependent libraries to be installed whenever Hadoop related tools or applications are installed on a computer. HomeBrew will install compatible libraries automatically without you searching all over the internet for them. This saves a lot of time and its one of our highly recommended tool to have for all Mac or Linux users.
To install it, open terminal application on your machine and copy-paste below command on the prompt
$> /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)”
Now to test if Homebrew is installed successfully, run this on prompt
$> which brew /usr/local/bin/brew $>
If you got something like above, then you are good with Homebrew and can proceed to next section.
WGET
Wget is a handy tool to download files using http, https or ftp protocols from internet. We will need this utility to download Hadoop binaries from Internet later in this post to install apache Hadoop on Mac or Linux machine.
To install it using homebrew, type following on terminal
$> brew install wget
This will install wget in /usr/local/Cellar by default and automatically create a symbolic link in bin/wget
To test if wget is correctly installed, run this in terminal
$> which wget /usr/local/bin/wget $>
SSH
Secure Socket Shell aka SSH is by default installed on Mac and Linux machines. In order to connect to Hadoop cluster, we need to setup a secure connection. Open System Preferences -> Sharing and enable Remote Login option as shown below.
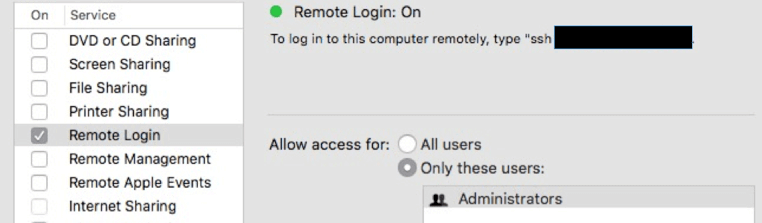
Next we need to generate secured public and private keys for remote logins as follows:
In your terminal, type following command
$> ssh-keygen –t rsa –P ‘’
This will generate keys under /home/<user>/.ssh folder.
To let hadoop access remote nodes, we need to add public keys. In our case, since its same machine, so we will just copy public key to the list of authorized keys as
$> cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Now you should be able to connect to server without it prompting for credentials. Type following in the terminal to test the connectivity
$> ssh localhost Last login: Jan 31 21:40:28 2018
If you get a message like above, then everything is working as expected and you are good to proceed further.
HADOOP
We recommend you to check this book if you want to be an expert in Hadoop.

Now, we can go ahead and download Hadoop binaries from apache website using wget utility. Let’s follow the steps as stated below and run them in the terminal:
Change directory where we want to install the hadoop, /usr/local is ideal for most users.
$> cd /usr/local
Download the latest stable version of hadoop from Apache’s website as
$> sudo wget http://mirror.nohup.it/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
Note, as of writing this post, Hadoop version 2.7.3 is the latest. There may be a newer stable release of Hadoop available in future, so please check below link to get latest release of Hadoop: http://hadoop.apache.org/releases.html#Download.
The downloaded file is a tar file which needs to be extracted before use, so run below command to untar it
$> sudo tar xvzf hadoop-2.7.3.tar.gz
We prefer to remove the version number from the directory name to keep it simple and easy to remember.
$> sudo mv hadoop-2.7.3.tar.gz hadoop
Next we need to configure Hadoop. So, open ~/.bashrc or ~/.bash_profile file on your home directory and add following environment variables in it.
## java variables export JAVA_HOME=$(/usr/libexec/java_home) ## hadoop variables export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib” export PATH=$HADOOP_HOME/bin:$PATH export PATH=$HADOOP_HOME/sbin:$PATH
Save the file and exit.
Next reload the configuration into memory so all new environment variables are effective as follows
$> source ~/.bash_profile
After this, if you print the value of a variable it should display it correctly. For instance
$> echo $HADOOP_HOME /usr/local/hadoop
Now your computer knows where Hadoop is installed but we need to configure Hadoop itself too; so it can run as a pseudo mode cluster. Follow below steps in terminal to do it.
Change directory
$> cd $HADOOP_HOME/etc/hadoop
Change following properties in hadoop-env.sh as
$> vi hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
Next open core-site.xml file and change it as follows
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hdfs/tmp</value> <description>base for other temp directories</description> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Now open hdfs-site.xml in terminal and change it as
$> cd $HADOOP/etc/hadoop $> vi hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
This basically tells hadoop that the replication is set to 1, meaning we won’t keep multiple copies of data blocks in our single node cluster. This is not recommended for production like environments. There you would like to set it at least 3 to prevent data loss in case of node failures.
Next open yarn-site.xml file in terminal and configure it as
$> vi yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
Now open mapred-site.xml file and configure it as follows
$> vi mapred-site.xml <configuration> <property> <name>mapred.job.tracker</name> <value>yarn</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
This is where MapReduce is configured and we are basically telling it that YARN will take care of resource management on our cluster.
We are all done with configuring Hadoop now. Next we need to start the Hadoop cluster and its processes. The way to do it is via Hadoop’s daemons. A daemon is a process which runs in the background silently. Hadoop comes with couple of them each for NameNode, Data node and YARN management.
Before we can start the daemon, we must format the NameNode so it starts fresh. Let’s do it as
$> hadoop namenode –format
Now start the distributed file system daemons as
$> start-dfs.sh # starts NameNode, DataNode & SecondaryNameNode
And then YARN daemon as
$> start-yarn.sh # starts ResourceManager & NodeManager
In few minutes, it will bring all processes UP and Running which we can confirm using jps command
$> jps –lm 5715 org.apache.hadoop.hdfs.server.namenode.NameNode 5799 org.apache.hadoop.hdfs.server.datanode.DataNode 5913 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode 6136 org.apache.hadoop.yarn.server.nodemanager.NodeManager 6042 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
If you have reached this far and output of jps command is similar to as shown above, then you have done it. You have successfully setup Apache Hadoop Cluster on a Mac or Linux Machine. Congratulations!!!
Here are our favorite books which would prove to be immensely helpful for anyone looking to learn Hadoop and related technologies. Please do checkout them.



You might be interested in learning how data engineers across the world are boosting their career using skills taught in this course – How to integrate ElasticSearch with Hadoop ecosystem

We hope that this post proves immensely helpful to you and your organization. In this article we have featured How to setup Apache Hadoop Cluster on a Mac or Linux Machine. We believe this will help you in starting your career as big data engineer.
If you liked this How to set up Apache Hadoop Cluster on a Mac or Linux Machine article, then do share it with your colleagues and friends. Do you have any questions or suggestions for us, please leave it in the comments section below.
Do not forget to sign up for our Free newsletter below.
[…] How to setup Apache Hadoop Cluster on a Mac or Linux Computer – step by step instructions on how to get started with apache Hadoop on a Macbook or Linux machine. […]
[…] Large number of files on Hadoop is a problem and how to fix it?How to setup Apache Hadoop Cluster on a Mac or Linux Computer Search […]
[…] our related posts How to Quickly Setup Apache Hadoop on Windows PC for windows users & How to setup Apache Hadoop Cluster on a Mac or Linux Computer for our MacBook or Linux […]
[…] on your personal MacBook or Linux OS computer, then you can check our post with step by step guide: How to setup Apache Hadoop Cluster on a Mac or Linux Computer Before we look into How to Quickly Setup Apache Hadoop on Windows PC, there is something that you […]
[…] If you are using a Macbook/Linux computer then refer this step by step guide on installing Hadoop on a Macbook. […]
[…] If you are using a Macbook/Linux computer then refer this step by step guide on installing Hadoop on a Macbook. […]
[…] If you are using a Macbook/Linux computer then refer this step by step guide on installing Hadoop on a Macbook. […]