

Ray Python is an open-source unified compute framework that offers powerful capabilities for scaling AI and Python workloads. With its easy-to-use APIs and distributed computing capabilities, Ray Python enables developers to efficiently parallelize and distribute their computations across a cluster of machines. In this blog post, we will explore the core concepts of Ray Python, get started with its installation and usage, and delve into its advanced features. We will also showcase real-world use cases where Ray Python has been successfully utilized for scaling AI and Python workloads. Additionally, we will provide code examples to demonstrate its functionalities.
Understanding Ray Python’s Core Concepts
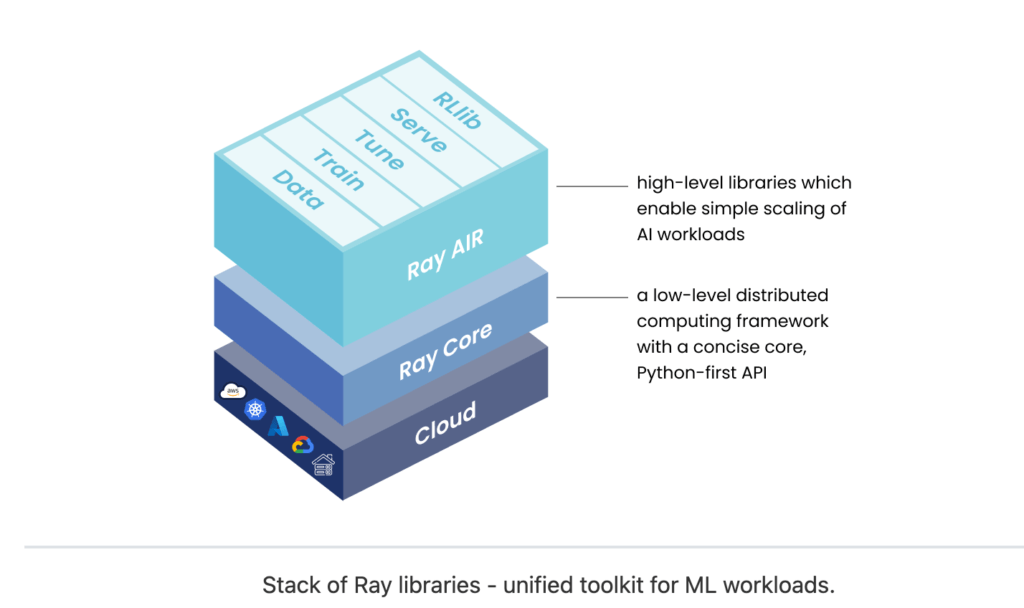
Ray Python is built on the concept of tasks, actors, and the Ray object store. Tasks are functions that can be executed in parallel, while actors are stateful objects that can maintain their state across multiple invocations. The Ray object store is a distributed in-memory data store that allows for efficient data sharing across tasks and actors. Ray Python also provides a runtime environment for managing distributed computing resources, such as remote CPUs and GPUs. This enables parallelism and distributed computing, making it easy to scale computations.
Getting Started with Ray Python
To get started with Ray Python, you need to install the Ray library using pip, the Python package manager. Once installed, you can import the Ray module in your Python code and start using its APIs. For example, you can use the ray.init() function to initialize the Ray runtime and connect to the Ray cluster. You can also use the ray.get() function to retrieve the results of a completed task or actor invocation. Here’s an example:
import ray
# Initialize Ray
ray.init()
# Define a simple task
@ray.remote
def my_task(x):
return x * 2
# Call the task remotely
result = my_task.remote(10)
# Retrieve the result
print(ray.get(result)) # Output: 20
# Shutdown Ray
ray.shutdown()
Scaling AI Workloads with Ray Python
Ray Python is particularly useful for scaling AI workloads, such as training large neural networks or processing massive datasets. You can use Ray Python to parallelize tasks, such as model training or hyperparameter tuning, across multiple machines in a distributed computing environment. This can significantly speed up the training process and improve resource utilization. Here’s an example of how you can use Ray Python to scale AI workloads:
import ray
# Initialize Ray
ray.init()
# Define a function for training a machine learning model
def train_model(data):
# Training logic goes here
pass
# Generate a list of data for training
data_list = [...]
# Parallelize model training across multiple machines using Ray
results = ray.parallel_map(train_model, data_list)
# Wait for all tasks to complete
ray.wait(results)
# Shutdown Ray
ray.shutdown()
Scaling Python Workloads with Ray Python
Ray Python can also be used to scale Python workloads beyond AI tasks. For example, you can use Ray Python to process large datasets, run simulations, or conduct experiments in parallel across multiple machines. Ray Python provides efficient ways to distribute data and computations, making it ideal for handling computationally intensive Python workloads. Here’s an example of how you can use Ray Python to scale Python workloads:
import ray
# Initialize Ray
ray.init()
# Define a function for processing data
def process_data(data):
# Data processing logic goes here
pass
# Load a large dataset
data = [...]
# Parallelize data processing across multiple machines using Ray
results = ray.parallel_map(process_data, data)
# Wait for all tasks to complete
ray.wait(results)
# Shutdown Ray
ray.shutdown()
Advanced Features of Ray Python
In addition to its core concepts, Ray Python also offers advanced features for handling more complex use cases. For example, it provides support for distributed computing with multiple drivers and workers, dynamic task scheduling, and fault tolerance. Ray Python also integrates seamlessly with popular Python libraries like NumPy, Pandas, and Scikit-learn, making it a versatile tool for various data processing and machine learning tasks. Here’s an example of using Ray Python’s advanced features for dynamic task scheduling:
import ray
# Initialize Ray
ray.init()
# Define a dynamic task
@ray.remote
def dynamic_task(x):
# Dynamic task logic goes here
pass
# Generate a list of data
data_list = [...]
# Submit dynamic tasks with varying sizes
results = []
for data in data_list:
result = dynamic_task.remote(data)
results.append(result)
# Retrieve the results
for result in results:
print(ray.get(result))
# Shutdown Ray
ray.shutdown()
Real-World Use Cases of Ray Python
Ray Python has been successfully adopted in various real-world use cases to scale AI and Python workloads. For example, it has been used for distributed machine learning, large-scale data processing, scientific computing, and reinforcement learning. Ray Python has also been integrated with popular deep learning frameworks like TensorFlow and PyTorch for distributed training of neural networks. Its flexibility, scalability, and ease of use make it a preferred choice for handling large-scale computations in Python.
Ideal Use Cases for Ray Python
Ray Python, as an open-source unified compute framework, is designed to scale AI and Python workloads efficiently. It offers various features for distributed computing, dynamic task scheduling, and fault tolerance, making it suitable for a wide range of use cases. Some ideal use cases for Ray Python include:
- Distributed machine learning: Ray Python can be used to scale the training of large machine learning models across multiple machines, allowing for faster training times and improved model performance.
- Large-scale data processing: Ray Python can efficiently parallelize data processing tasks, such as data filtering, aggregation, and transformation, to process large datasets in parallel, saving time and resources.
- Scientific computing: Ray Python can be used for distributed simulations, numerical computations, and other scientific computing tasks, where the processing of large datasets or complex computations can benefit from distributed computing.
- Reinforcement learning: Ray Python provides built-in support for distributed reinforcement learning, allowing for efficient training of reinforcement learning agents across multiple machines or clusters.
- High-performance computing: Ray Python can be used for parallel computing tasks, such as simulations, optimization, and complex computations, where distributed computing can significantly speed up the processing time.
When Ray Python isn’t the best fit
However, there are cases where Ray Python may not be the best fit. For example:
- Small-scale computations: If you are working on small-scale computations that can be easily handled by a single machine, using Ray Python may introduce unnecessary overhead and complexity.
- Simple, single-node tasks: If you have simple tasks that do not require distributed computing or parallel processing, using Ray Python may be overkill and not provide significant benefits.
- Projects with minimal resource constraints: If you have ample resources, such as computing power and memory, available on a single machine, using Ray Python for distributed computing may not be necessary.
- Projects with time or budget constraints: If you have limited time or budget constraints and cannot invest in the setup and maintenance of a distributed computing environment, using Ray Python may not be feasible.
In summary, Ray Python is ideal for use cases that involve large-scale data processing, distributed machine learning, scientific computing, reinforcement learning, or high-performance computing. However, it may not be necessary or feasible for small-scale computations, simple tasks, or projects with minimal resource or time constraints. It’s important to carefully evaluate your specific use case and requirements before deciding to use Ray Python or any other distributed computing framework.
Learn about Ray Python
There are several good learning resources available to learn about Ray Python, the open-source unified compute framework. Some of the popular ones include:
- Official Ray Python Documentation: The official documentation for Ray Python is a comprehensive resource that provides detailed information on various aspects of Ray, including installation, concepts, API references, tutorials, and examples. It’s a great starting point for beginners to get familiar with Ray Python.
- Ray GitHub Repository: The Ray GitHub repository (https://github.com/ray-project/ray) contains the source code for Ray Python, along with extensive documentation, issues, and discussions. It’s a valuable resource for understanding the internals of Ray and exploring the latest features and updates.
- Ray Python Website: The official Ray Python website (https://ray.io/) provides an overview of Ray, its features, use cases, and resources for learning, including tutorials, documentation, and community forums.
- Ray Python Tutorials: Ray Python offers a range of tutorials that cover different aspects of the framework, from basic to advanced topics. These tutorials provide step-by-step instructions, code examples, and hands-on exercises to help users understand and implement various features of Ray Python.
- Ray Python Community: The Ray Python community is an active and supportive community of developers, users, and contributors. The community provides resources such as forums, mailing lists, and chat channels where users can seek help, ask questions, and learn from each other’s experiences.
- Ray Python YouTube Channel: Ray Python has an official YouTube channel (https://www.youtube.com/c/RayProject) that features video tutorials, demos, and talks related to Ray Python. These videos provide visual demonstrations and explanations of Ray’s features, use cases, and best practices.
- Online Courses and Blogs: There are several online courses and blogs available that cover Ray Python in depth. These resources provide comprehensive tutorials, case studies, and practical examples to help users understand and implement Ray Python in real-world scenarios.
- Books and Documentation: There are books and other written resources available that focus on Ray Python, providing in-depth coverage of the framework, its features, and best practices. These resources can be useful for users who prefer a more structured and in-depth approach to learning.
You might like:
- Mastering Apache Kafka Architecture: A Comprehensive Tutorial for Data Engineers and Developers
- The Best Data Processing Architectures: Lambda vs Kappa
- Python Generators Unleashed: Harnessing Performance and Efficiency for Data Processing
In this blog post, we explored how Ray Python, an open-source unified compute framework, makes it easy to scale AI and Python workloads. We covered its core concepts, demonstrated how to get started with Ray Python, and showcased its advanced features with code examples. We also discussed real-world use cases where Ray Python has been successfully utilized. Whether you’re working on AI tasks, large-scale data processing, or other computationally intensive Python workloads, Ray Python can be a valuable tool to optimize performance and improve scalability. Give it a try and unlock the full potential of distributed computing in Python!
We hope you found this blog post informative and helpful. If you have any questions or comments, feel free to leave them below. Thank you for reading!