

 In big data world, things are changing too quickly to catch and so is the size of data that an application should handle. If there was an application designed a year ago to handle few terabytes of data, then it’s not surprising that same application may need to process petabytes today. The three Vs of the big data world; Volume, Velocity and Variety are advancing to unbelievable levels today. Nobody could have imagined the pace with which new data is getting generated now. To store and process this much of data is a big challenge today. There are many new technologies that have erupted in last few years to take up this challenge. But irrespective of which technology we choose, there’s a need to adopt a good overall architecture in the beginning.
In big data world, things are changing too quickly to catch and so is the size of data that an application should handle. If there was an application designed a year ago to handle few terabytes of data, then it’s not surprising that same application may need to process petabytes today. The three Vs of the big data world; Volume, Velocity and Variety are advancing to unbelievable levels today. Nobody could have imagined the pace with which new data is getting generated now. To store and process this much of data is a big challenge today. There are many new technologies that have erupted in last few years to take up this challenge. But irrespective of which technology we choose, there’s a need to adopt a good overall architecture in the beginning.
This overall architecture must handle today’s demand well enough but should also adjust to the future growths which could easily be 100x of today’s size. In other words, the architecture must be linearly scalable; meaning new machines could be added into the system to scale its capacities and capabilities. In this article – Best Data Processing Architectures: Lambda vs Kappa. We will review two data processing articles. Before we start, we must understand challenges of real-time analytics. So, let’s dive into it first.
Challenges of Real time data analytics
This is one of the most common requirement today across businesses. In simple terms, the “real time data analytics” means that gather the data, then ingest it and process (analyze) it in near real-time. As seen, there are 3 stages involved in this process broadly:
- Gather data – In this stage, a system should connect to source of the raw data; which is commonly referred as source feeds. After connecting to the source, system should read that data in batch or continuous manner (in case of real-time), and finally store it some on distributed system such as Hadoop’s distributed file system (HDFS).
- Ingest – This is 2nd stage, were gathered data needs to be transformed in a structured or semi structured format so as to ease up further analytical processing over it in next stage. (based on system design, there could be thin line between this stage and gather data stage). Apache hive is one of the tools that is used in this stage to access structured data in hadoop. If you want to use hive, then I recommend reading this article.
- Process – This is the place where raw data is converted into actionable insights. The results of this process may answer business queries such as how many customers bought X product in month of June while NFA games were shown on TV, etc. Such kinds of insights are very critical for businesses to succeed by offering right products to right customers and at right time. For this stage, there are various tools that can be used such as ElasticSearch with Kibana (to generate real-time amazing dashboard) or Spark or even Hive can be used to generate batch views.
On a quick side note, Checkout this course which has helped many data engineers excel at their jobs.
The core principle of real-time data is how fast data can be loaded and analyzed into meaningful insights. In other words, the data is in motion and continuous and what matters most is how fast data is processed. This is easier said than done. It’s very challenging in real scenario and there are many things that need to be planned for a successful implementation. For instance, real-time requirements usually have very tight deadlines. If not, then who needs real-time systems? A batch processing system will be enough if there are no deadlines, right? But that’s a discussion for some other time.
Data Processing Architectures
There are many data processing architectures used to implement data applications today. Here we will discuss two which are widely used:
- Lambda Architecture
- Kappa Architecture
Now its time to look into The Best Data Processing Architectures: Lambda vs Kappa.
Here are few good books I highly recommend on the subject: book, book & book.
Lambda Architecture
The idea of Lambda architecture was originally coined by Nathan Marz. Basically he’s idea was to create two parallel layers in your design. One layer will be for batch processing while other for a real-time streaming & processing.
This is how a system would look like if designed using Lambda architecture.
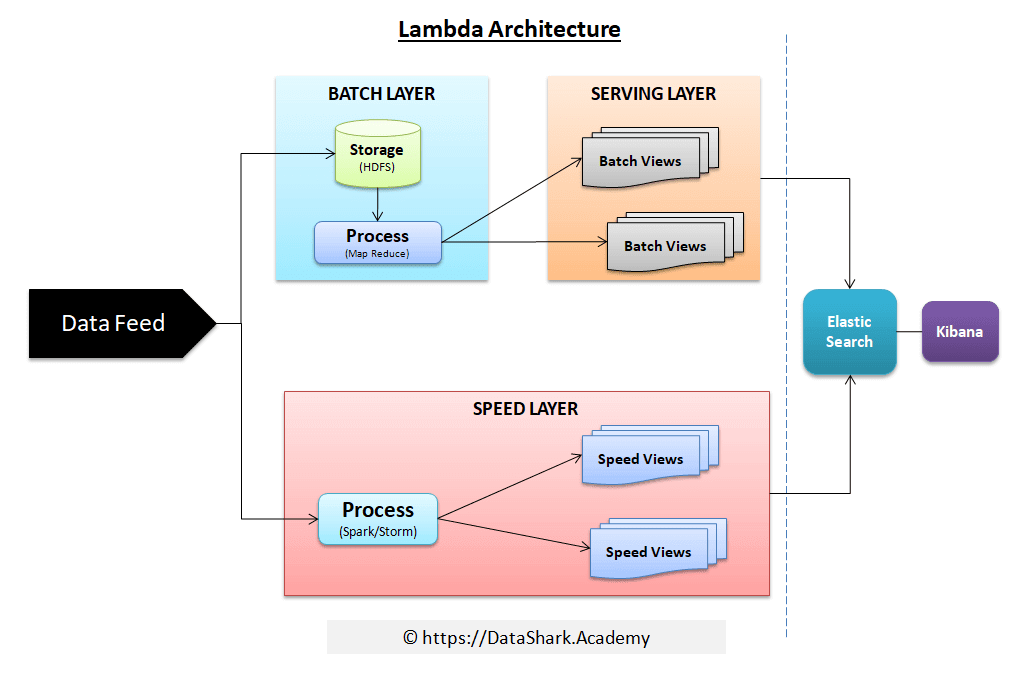
Lambda architecture as a data processing architecture has three layers:
- Batch Layer
- Speed Layer
- Serving Layer
Layers in Lambda Architecture
The streaming data is raw data that is coming from source systems (aka feeds). Same data is sent to batch layer and speed layer. Inside batch layer, the data is stored preferably on a distributed storage system such as Hadoop distributed file system (HDFS). The stored data from HDFS is then transformed & analyzed using custom map reduce jobs to generate resultant datasets which will be stored inside Serving layer (could be same as HDFS or Oracle systems or ElasticSearch) as “Batch Views”. The serving layer is responsible to send results of the query from users. For instance, an ElasticSearch system may be used as Serving Layer in this case; which is feeding this data results to a pre-configured dashboard (built using Kibana). With Kibana, real-time and dynamic dashboards can be created which look like as shown below.

So, we discussed two layers; Batch and Serving until this point. Now let’s move on to Speed Layer.
The speed layer can be built using Spark streaming or Storm technologies. Basically, in this layer same feed is fed as packets of data. The streaming engine consumes one packet at a time, process it (meaning applies analytical logic on that packet of data, stores the result in memory or in persistence manner). This is where real-time processing is happening.
You might be interested in

To understand it better, let’s assume that we want to count occurrence of each word in this post. So, we will send this post as a text file to Speed layer, which will split this entire file into various packets of data. Each packet of data consists of one line from the post. Then stream process will receive this packet, split each line into individual words and then increment the counters of each word from previous counts stored in memory. So, if you can see the end result here in real-time, then you would notice the counters of each word is changing very rapidly. These results will be fed to systems like ElasticSearch which can be queried as discussed in case of batch layer.
An important point to understand here is about updates in the results. In case of batch layer, new data is being stored and map reduce process is running over entire data set to generate updated batch views (older batch views are replaced with new ones). In case of speed layer, this is happening in continuous manner in real time. There’s no or minimal lag in updating the results when querying results from speed layer.
Quick side note, here is a list of related posts that I recommend:
- 6 Reasons Why Hadoop is THE Best Choice for Big Data Applications – This article explains why Hadoop is the leader in the market and will be one for long long time.
- What is MobaXterm and How to install it on your computer for FREE – If you haven’t used MobaXterm before, then I highly recommend you to try it today. I guarantee you will never look back.
- Learn ElasticSearch and Build Data Pipelines – This is actually an intro to a very comprehensive course on integrating Hadoop with ElasticSearch. This is one of key skills for advancing your data engineering career.
- How to Quickly Setup Apache Hadoop on Windows PC – step by step instructions on how to get started with Hadoop on windows PC.
- Installing Spark – Scala – SBT (S3) on Windows PC – detailed instructions on how to get started with Spark, Scala and SBT for window users.
Kappa Architecture
The idea of Kappa architecture was originally presented by Jay Kreps. In this architecture, batch layer is absent. Kappa architecture is ideal for real-time applications as it focuses only on speed layer.
Here’s how a system would look like if designed using Kappa architecture.

In Kappa architecture, we have two layers as:
- Real time (Speed) Layer
- Serving Layer
In this architecture, streamed data is fed into real-time layer which could be spark streaming or storm framework. After processing the data, the results are sent over to Serving Layer. At Serving layer the results are stored in a manner for easy query by external systems. Here also, ElasticSearch like systems with Kibana Dashboard may be ideal fit.


The advantage of Kappa architecture over Lambda architecture is in simplicity. With Lambda, you would need to maintain two different processes and possibly different set of codes which can put pressure on small budget projects. In Kappa, there’s only one level of process and one set of code so it’s cheaper to implement. Also from end-user perspective, with Kappa there’s only one plug-in required to read the data while in Lambda there are two different views for batch and real-time data results.
The question isn’t about which architecture is the BEST out of Lambda or Kappa. As we learned, it’s a matter of requirement and business case. Both architectures fulfill their own purposes and use cases.
We believe that cloud computing will be the next big thing in the industry. In fact it has already become a highly sought after skill. That’s why engineers from 74 countries have taken this course. We recommend you to check this out too.

We hope that this article proves immensely helpful to you and your organization. In this article we have featured Best Data Processing Architectures: Lambda vs Kappa.
If you liked this – Best Data Processing Architectures: Lambda vs Kappa article, then do share it with your colleagues and friends. We would love to hear your success stories in the comments section below.
[…] The Best Data Processing Architectures: Lambda vs Kappa – Confused which architecture to use while designing big data applications. This article can help. […]
[…] The Best Data Processing Architectures: Lambda vs Kappa – Confused which architecture to use while designing big data applications. This article can help. […]
[…] Pingback: The Best Data Processing Architectures: Lambda vs Kappa […]