

 Apache Spark is a computing engine with many libraries to process huge amount of data in parallel over a distributed cluster. The beauty of apache spark is that it can work on a single machine in same way as it would on a cluster of thousands of machines.
Apache Spark is a computing engine with many libraries to process huge amount of data in parallel over a distributed cluster. The beauty of apache spark is that it can work on a single machine in same way as it would on a cluster of thousands of machines.
We have used clusters as big as over 1000 nodes in it and kicked various spark programs. It is amazingly powerful.
Apache spark provides speed at which it can compute complex results. In fact it is so much powerful that even Facebook which originally created Apache hive, have switched it’s processes to use Spark instead. There’s no other company in the world that has to deal with data more than what Facebook does every day.
History of Apache Spark
Apache spark started in 2009 at the time when Hadoop’s MapReduce was the dominant player as the distributed computing engine across the industry. To great extent MapReduce was successful in solving big data problems. But the joy didn’t last longer. Soon data engineers and data scientists realized the limitations and challenges to work with MapReduce.
One of the prime challenge while working with MapReduce was developing Machine Learning applications. As Hadoop’s MapReduce architectural principle is based on divide and conquer, it makes practically impossible to write machine learning algorithms which needs multiple traversal across same dataset.
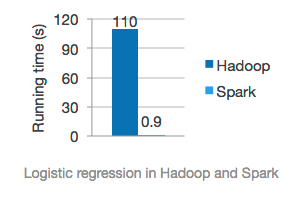
MapReduce’s another challenge was its underlying framework is largely dependent upon disk I/O operations.
source: spark.apache.org
In other words, Hadoop MapReduce would aggressively store intermediate results onto disk before passing on the buck to the next task in the queue. As disk I/O operations are multi-fold slower than memory operations (adopted by Apache Spark), MapReduce is way too slower compared to Apache Spark.
Related Posts:
- Spark Streaming with Kafka
- Installing Spark – Scala – SBT (S3) on Windows PC
- How to setup Apache Hadoop Cluster on a Mac or Linux Computer
- Learn Complete ELK Stack
- How to Quickly Setup Apache Hadoop on Windows PC
- How to compile unmanaged libraries within a SCALA application
Apache Spark Architecture
Apache Spark is a unified computing engine with a set of libraries built over it to facilitate parallel data processing on computer clusters.
Initially spark came up with RDD as the main data processing unit. In fact even today in spark 2.x it is available if someone wants to do low-level programming.
RDD stands for Resilient Distributed Dataset. In a nutshell RDD is a collection of JVM (Java Virtual Machine) objects which are distributed across the cluster and are immutable meaning once the data is initialized in the object, it can’t be changed.
The Low level APIs in apache spark’s architecture consists of RDDs & distributed variables (Broadcast variable and Accumulator variable).
The structured APIs provide Dataframes, Datasets and Spark SQL. A dataframe is a virtual table, like a row & column format in which data will be stored. This is similar to how physical tables are represented in relational databases such as Oracle.

Internally they are built on top of RDDs but they provide more optimized interface to RDDs. There’s lot of optimization built up in structured APIs for users which is automatically taken care of without user doing anything.
If you are new to apache spark, then we highly recommend you to start with learning structured APIs.
Spark streaming is another great feature that comes inbuilt inside spark. Spark streaming allows us to read and write a stream of data and perform all sorts of computations that are available with structured or unstructured APIs.
Apache Spark also provides Machine Learning (MLlib) libraries through its advanced analytics APIs in addition to GraphX APIs which are ideal for use cases using graphs.
Why Apache Spark prefer Immutable data units?
With immutable data units, apache spark doesn’t have to keep track of what was changed, who changed it and when a data unit was changed. It will be a nightmare to keep track of it in a distributed environment.
History of Spark APIs
Spark started with RDD as it’s main API for users to develop spark programs. In Spark 2.x, structured APIs such as Dataframe and Datasets took over the unstructured APIs (RDD).
If your program is built using structured APIs, Spark will automatically provide key optimizations to run the program in shortest time possible. Good luck if you want to do same with RDDs.
This makes Dataframes many fold faster than RDDs.
Datasets are similar to dataframes with only difference being that dataframes are untyped collection of data while datasets are typed collection of data.
When we create a dataframe, internally it is a dataset of type Row. Row is a data type provided by Spark. It is an optimized binary data format that makes dataframes fast.
On the other hand, Datasets can have columns of type String, Long, Integer, etc which makes it a typed collection of data.
Since datasets are managing & type-checking for individual columns inside each record, it is slower than dataframes.
RDD vs Dataframe vs Dataset
It is a common confusion among data engineers about which API is fit for their spark program. To help you make this decision, consider following guidelines:
-
Choose RDDs when:
- you need to tightly control how your data will be partitioned & stored on the cluster.
- there’s some functionality that isn’t supported in structured APIs yet.
- you know what you are doing. In other words, you are an expert in writing spark applications.
- you are ready to re-invent the wheel and handle optimizations at every stage of your program such as while reading from source, computing results, tweaking execution plans and finally writing the results to some kind of storage.
-
Choose Datasets when:
- you need type checking at compile time. In other words, your application must ensure that data types are as what is expected by the business use case.
- it is OK to take a little performance hit over untyped data types.
-
Choose Dataframes when:
- above two options aren’t valid for your program.
- by default use dataframe for your program unless you really care of data partitioning and type checking at compile time.
How Apache Spark Works
Now lets’ look at how a spark program really works internally.
source: spark.apache.org
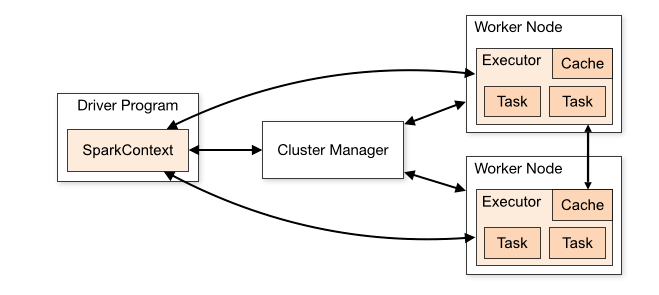
An apache spark application is started from a client program. A client program could be running within same cluster or could be on a remote location. The client program first submits the request to the cluster manager for allocating resources (machines) for spark application to run on.
Apache spark supports 3 types of cluster managers:
- Standalone Spark Cluster manager (in-built in spark)
- YARN (famous for Hadoop clusters)
- Mesos (lets user manage resource allocation kind of opposite of YARN)
Irrespective of which cluster manager you are using, cluster manager will assign a node and copy the driver program on it (as you see on the left hand side of above image).
Driver program must have a SparkSession or SparkContext object defined in the code. SparkContext is the entry point in the spark cluster of executors and provides a communication layer for driver to talk to its executors directly.
sample code
//create a SparkSession object
val spark = SparkSession.builder()
.appName("DataShark Academy Sparks")
.getOrCreate()
After driver program is kicked, it will again go back to the cluster manager and ask it to provide machines (worker nodes) to run spark tasks which would run inside a JVM program called ‘executor’ and copy the code to those nodes. An executor may have one or more tasks running at time in it.
After kicking the executors, cluster manager sends information about all executors back to driver. At this stage, driver starts talking directly with its executors.
Upon completion of all the tasks, each executor keep updating the driver and it’s driver’s responsibility to assign any more tasks needed to the available executors.
Once the entire list of spark tasks are completed, driver prepares the final output for the client program and asks cluster manager to stop the executors. At this point, driver will exit and cluster manager will recover its assigned resources back to its availability pool.
Here are more advanced topics on Apache Spark which you might like:
- Spark Streaming with Kafka
- Mastering Apache Kafka Architecture: A Comprehensive Tutorial for Data Engineers and Developers
In this post, you have learned about Apache spark, the fastest distributed computing engine existing today. If you have any questions, please feel free to ask in comments below.
[…] Unlocking Big Data: Exploring the Power of Apache Spark for Distributed Computing […]