

 Apache Kafka builds real-time streaming data pipelines. A real-time streaming data pipeline basically means that a channel through which data can be moved from one system to another in small batches. We have seen similar systems in our lives much before Apache Kafka came into existence.
Apache Kafka builds real-time streaming data pipelines. A real-time streaming data pipeline basically means that a channel through which data can be moved from one system to another in small batches. We have seen similar systems in our lives much before Apache Kafka came into existence.
Remember text SMS that you send from your phone to someone else and it’s instantly delivered to the recipient. Apache Kafka is a similar system that enables this kind of data transfer between one or more systems.
In addition to real-time streaming data pipelines, Kafka is robust enough to support batch data pipelines too. A batch data pipeline is like where some system is sending the data but recipient isn’t really eager to read it instantly. It can process the message at a later time when a large chunk of messages are gathered. This is a very common architecture used in lots of services provided by companies.
Apache Kafka is fault tolerant meaning that if a server is down then another server can start from same point without causing data loss. Another critical feature of Apache Kafka is its speed. It’s amazingly fast.
Why Apache Kafka
Let’s look at some reasons why we need Apache Kafka and why over 2000+ companies are using it in their production.
1. Blazingly Fast Messaging System
Apache Kafka is crazy fast compared to traditional messaging systems. It is fault tolerant as well, meaning that in addition to providing speed it also ensures data isn’t lost in transmission. Due to this feature, Apache Kafka can replace a traditional messaging system such RabbitMQ or ActiveMQ.
2. Stream Processing
There are many use cases where a system is constantly generating new data which needs to be consumed and processed. Apache Kafka can provide the real-time data streaming capabilities. For processing this stream of data, we can use Apache Spark which is ideal solution for aggregating results over large data sets.
3. Decoupling Systems
Apache Kafka is a great example of decoupling systems. Suppose there’s a system A which is producing data and sending to system B. The way the architecture is designed is that system A has to wait for an acknowledgement from system B before sending the next packet.
This kind of architecture is very common in traditional systems but it doesn’t work nicely. It brings tight coupling (dependency) between two systems and if one of the system is down or slow, it will impact other system too.
Apache Kafka can solve this problem without any additional efforts from design team. It has inbuilt concept of Kafka producers (source systems), Kafka consumers (target systems) and acknowledgement (ACK). We will come back to ACK later in this post.
BECOME APACHE KAFKA GURU – ZERO TO HERO IN MINUTES

Typical Kafka System
This is how a typical Kafka system would look like:
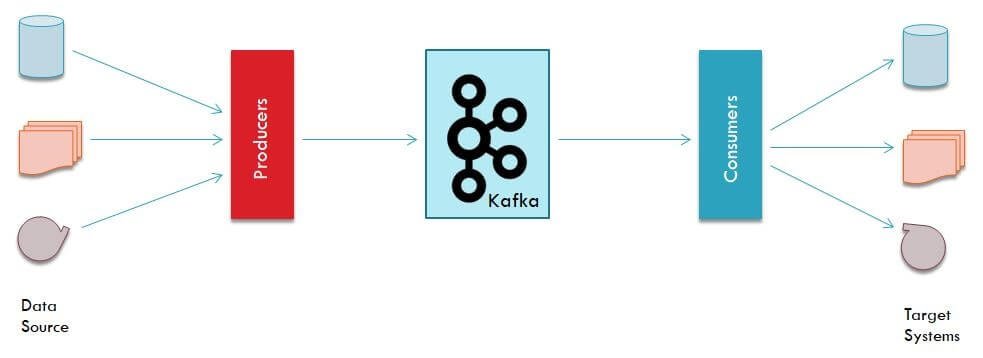
A data source system could be a database, a message queue, file or even another instance of Kafka. This system is where is data is lying or being generated.
A Kafka producer is a program that will read the data from a data source and create data packets to be sent to Kafka cluster.
Kafka cluster is a network of servers which will receive those data packets and store them temporarily (default 2 weeks) in its underlying topics.
A Kafka consumer is another program that will read those data packets from Kafka cluster and either do some analysis on that batch of data or send it to some target system which could be a database or file or another Kafka data pipeline.
Real time vs Batch Data Pipelines
Kafka works great with real-time data pipelines which means that as soon as data is received from a Kafka producer, it is sent to a Kafka topic and a consumer immediately processed it.
Real Time Pipeline
In a real-time architecture, you might have some data sources which are producing data at fast rate. For instance there would be website with millions of visitors. The company wants to understand the behavior of their visitors so what they are doing is capturing the web logs and sending them over to a Kafka cluster for further processing.
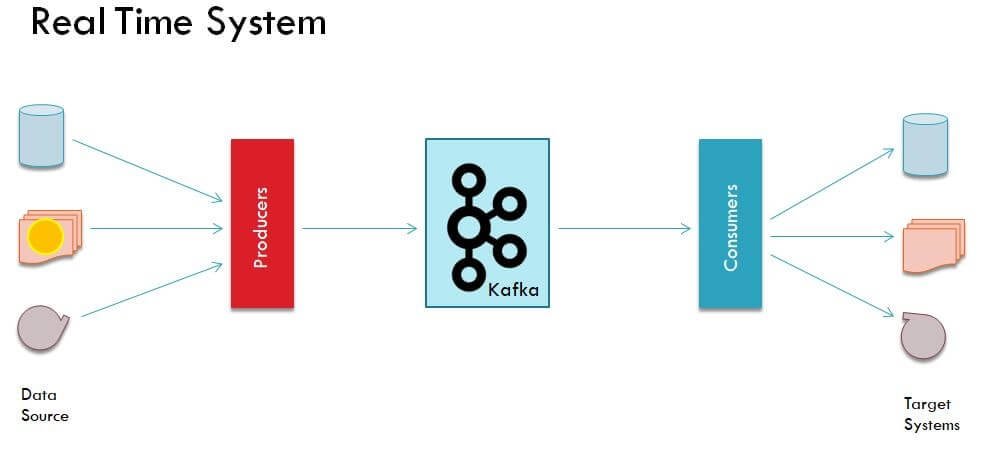
Once Kafka cluster receives those data packets from web logs, it pass them over to consumers. Here a consumer could be Apache Spark program which basically reads each packet and aggregates the data and generates some sort of analytics on user behavior.
At the end of spark program, the result can be persisted into a reliable storage such as a database or on Hadoop’s distributed file system. You can also stream the results directly to some dashboards for example; the result is consolidated into an ElasticSearch index and from there onwards a Kibana dashboard is reading. Kibana provides real-time dynamic dashboards.
We have a detailed course on how to use ElasticSearch with Hadoop. In this course you will learn how to move data between various systems and also create dynamic dashboards using Kibana.
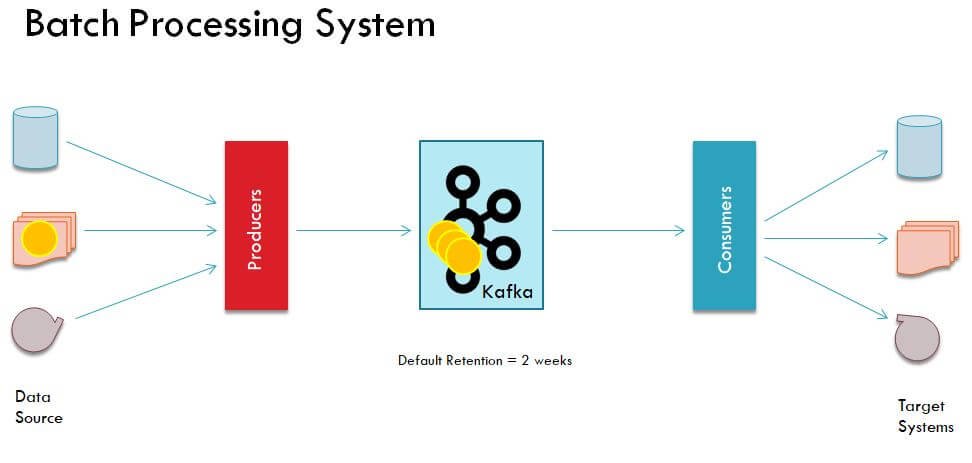
Batch Data pipeline
A batch data pipeline is much more relaxed than a real-time data pipeline. In a batch architecture, you may have a producer sending data at high-speed to Kafka cluster but consumer isn’t reading each packet instantly. Instead it is running once say every hour or once a day to process all accumulated data.
This type of applications are very common especially to perform non critical tasks. In this type of applications as well, the final results could be sent to some kind of storage or dashboards based on business requirements.
We hope you liked this post. If you are interested in learning more then we have a course for Apache Kafka Guru – Zero to Hero in Minutes.
[…] When we run this, you should get following output in real time database […]