

 There are multiple reasons for large number of files on Hadoop. Hadoop has its own file system to store data in form of files; and its called Hadoop Distributed File System or HDFS in short. Any data that is present in Hadoop will end up being stored on its distributed file system. But hold on, isn’t Hadoop originally created to handle large amounts of data? If so, why do we need to worry about large number of files in first place? If Hadoop is designed to store huge amount of data in form of files, then there will be equivalently high number of files in it. So why large number of files on Hadoop is a problem?
There are multiple reasons for large number of files on Hadoop. Hadoop has its own file system to store data in form of files; and its called Hadoop Distributed File System or HDFS in short. Any data that is present in Hadoop will end up being stored on its distributed file system. But hold on, isn’t Hadoop originally created to handle large amounts of data? If so, why do we need to worry about large number of files in first place? If Hadoop is designed to store huge amount of data in form of files, then there will be equivalently high number of files in it. So why large number of files on Hadoop is a problem?
This is correct that Hadoop is meant to store and process huge amount of data but what we want to discuss in this article is how large number of files on Hadoop can create various problems in long run. In order to understand this clearly, we need to first understand how files are stored on HDFS. So, let’s talk about that first;
Hadoop stores data in form of individual blocks ranging from 128MB to 256MB in size. In other words, say you have a file of 1000MB, it will be stored in 1000MB/128MB = ~8 blocks internally on HDFS. If block size is 256, then total number of blocks that 1000MB file will take; will be ~4. If you do the math, block size of 256MB will provide better storage efficiency (less free space wasted inside the last block) 3.9 blocks vs 7.8 blocks in case of 128MB block size. But this assumption is true if each file is around 1000MB on the cluster but that is not the case in reality. The storage efficiency may change with different file sizes stored on HDFS.
But still this doesn’t make Hadoop less important in data processing engine today. It is widely accepted across the world for good reasons. I recommend you to read more about it in 6 Reasons Why Hadoop is THE Best Choice for Big Data Applications. Now lets talk a bit about how data is internally stored and managed at core level.
Hadoop Architecture – HDFS
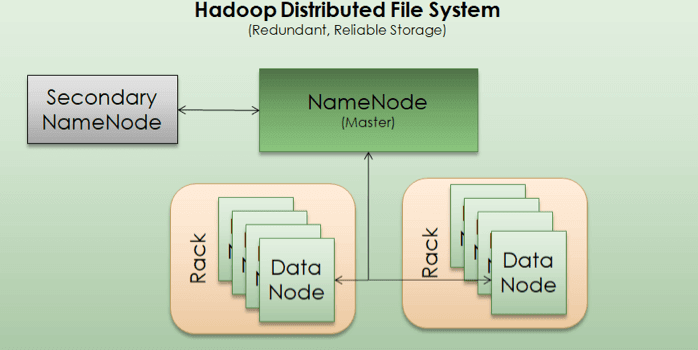
NameNode
As we learned above that files are stored in form of blocks on disk. So, there’s a need for a catalog system which can locate each block of a file across distributed machines. In addition, Hadoop also replicates each block three times so it has 3 different data nodes where copy of same block will be saved in.
To manage each file and location of its data blocks, a machine is designated as NameNode.. It is same kind of machine as data node but with limited storage and memory as its prime job is to maintain an index of data blocks and not the actual data.
NameNode does not store actual data as such but only metadata about the files and its blocks. So if a NameNode is down or crashed, system won’t be able to access data blocks and whole setup will be jeopardized. Right. This is why to avoid having NameNode as a single point of failure; there’s a backup of NameNode also. This is called Secondary NameNode. In case a NameNode fails, Secondary NameNode will take over the cluster. This is done pretty autonomously by Hadoop itself.
Secondary NameNode
As explained in NameNode section, secondary NameNode is the backup of Primary NameNode and is used to avoid single point of failure in the system.
Data Node
Data node is where the actual data blocks are stored. Each block can be around 128MB or 256MB depending upon how a cluster is configured. The Data nodes are responsible for serving read/write requests from client systems, or block creation/deletion/rename requests from NameNode. In order to avoid loss of a data block, they are usually replicated on other Data nodes.
By default, Hadoop recommends a replication level of 3 meaning a data block will have at least 2 more copies of itself. As Data Nodes are small and consists of bare minimum components unlike a regular laptop or desktop, they are stored in stacks on racks. A rack may hold 10-30 data nodes in a typical setup and an organization may have tens of hundreds of racks in its data center. The default configuration is to save first copy of a block in a data node stored on the same rack as actual data block, while second copy is stored in a different rack to deal with rack level failures. This approach provides well enough speed as well as fault tolerance against data loss in most of the cases.
This is how a High end Server looks like for a high-end hadoop cluster. It costs big bucks. Imagine a data center with thousands of such nodes. Typical hadoop clusters have small and cheaper hardware but industry is shifting towards high-end nodes to boost overall network speeds.
But why large number of files on Hadoop is a problem?
Well, if you didn’t notice yet, there’s only one NameNode handling 100s or 1000s of DataNodes with millions of data blocks. All this catalog information is stored in NameNode’s memory which is limited. Read it again, catalog information is stored in NameNode’s memory, which is limited. This is the reason why we need to be careful what all data is stored on Hadoop that NameNode will be tracking. In other words, the problem which we are discussing in this post isn’t about storage capabilities of Hadoop but tracking or cataloging capability of a single machine with limited memory.
You will think why can’t we increase memory or add two NameNodes to solve this problem? Well, we can increase memory but only to an extent. Imagine a NameNode is given 50TB of memory (this is absurd in most use cases; but just imagine for sake of explanation). So, now it can store virtually unlimited amount of catalog information, right? Right it can. But now the problem will be to scan that memory for a 2x, 4x, 8x, 16x, 32x core CPU? How much time CPU will take to scan 50TB of memory to locate all data blocks for a file?
If you decided to go with 2 NameNodes instead of one in previous example, then you will still have to create a master above those 2 that will tell which file is catalogued in which NameNode? This is not a solution either.
So, it is very important to keep catalog as optimized as possible.

Now we know that number of files shouldn’t be let growing uncontrollably in NameNode, it’s time to understand the reasons for large number of files on Hadoop. As many people do not know that Hadoop does not just store data files but all other stuff too which can be substantially high in quantity compared to actual data. Here are few of them;
- Data files – actual data; files have names as part-m-00000 or part-r-00000
- Log files – application container logs; by default created at /app-logs/<username>/logs
- .Trash – by default created at /user/<username>/.Trash
- /tmp – temporary files at /tmp location
- MapReduce History files – by default created at /mr-history/tmp/<username> location
- User files – by default at /user/<username>
Quick side note, here is a list of related posts that I recommend:
- The Best Data Processing Architectures: Lambda vs Kappa – Confused which architecture to use while designing big data applications. This article can help.
- 6 Reasons Why Hadoop is THE Best Choice for Big Data Applications – This article explains why Hadoop is the leader in the market and will be one for long long time.
- What is MobaXterm and How to install it on your computer for FREE – If you haven’t used MobaXterm before, then I highly recommend you to try it today. I guarantee you will never look back.
- How to Quickly Setup Apache Hadoop on Windows PC – step by step instructions on how to getting started with Hadoop
- Learn ElasticSearch and Build Data Pipelines – Find out why this course is critical for any data engineer.
- How to avoid small files problem in Hadoop – This post provides steps to avoid small files problem in Hadoop. It is a must read for anyone working on Hadoop.
As seen above, there can be multiple different types of files that are generating on HDFS. Some files are due to data being copied onto HDFS, while others are just logs and temporary files which may not be needed after few days.
Let’s focus on /app-logs/<username>/logs for now just to get a feel about extra files that are created in HDFS.
When a process is executed say a map reduce job or spark job, Hadoop’s resource manager – YARN allocates containers to that job. Then job uses those allocated resources to run its program. In parallel, YARN generates logs for its containers and stores them at /app-logs//logs location or simply at /logs directory on HDFS. Note: The log location depends on how YARN is configured. But nevertheless, YARN will generate these logs every time a process is executed on its resources. In distributed environment with 100s of nodes (aka machines) on the cluster, the same process may run on multiple nodes in parallel and will generate logs for each container node.

This means that if YARN allocated 10 nodes to a job, it will end up creating 10 different container logs (one on each node). Now each node may be handling only a small part of the overall job and so it will generate smaller log files. But remember we aren’t concerned about size of the files but Why Large number of files on Hadoop is a problem? So, to re-iterate what we just discussed, a program may end up creating multiple log files on a hadoop cluster which will eventually be saved at /app-logs/<username>/logs or /logs location.
If you want to be an expert in Hadoop, then we highly recommend following book, book, book for you.
YARN UI
Open YARN Resource Manager GUI by clicking on http://localhost:8088/cluster/apps/NEW_SAVING. Remember you must have Hadoop and YARN installed before it will work. If you want to setup Hadoop on your computer, then follow instructions here. After screen opens, it will look like

Now click on Local logs on left side panel and this screen will open
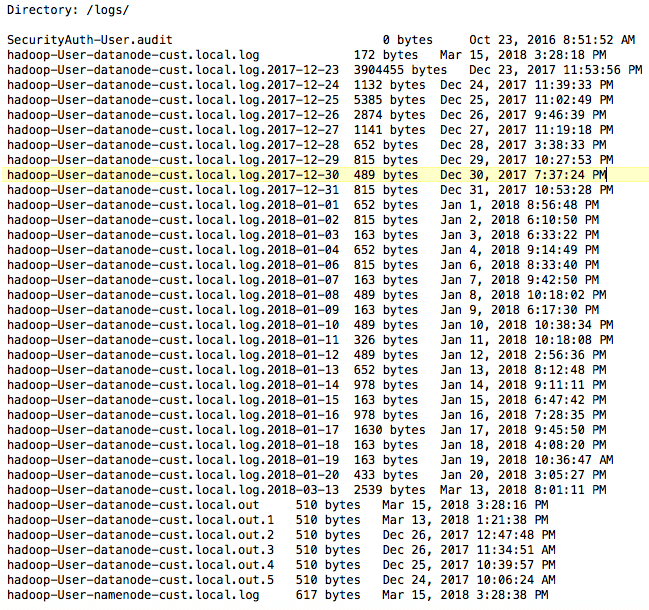
As seen, there are different types of log files created at this location. Often administrator team overlook these logs while accounting for space and file count problem. It is advisable to implement some cron jobs (processes running automatically at regular intervals) to clean these log files and any other temporary files. This simple change can boost Hadoop’s performance greatly and help in controlling costs as well.
We have another post explaining how to control number of temporary files created by hive and how to merge smaller files to larger ones in hive to reduce overall count of data files.
Checkout this course which has helped many data engineers excel at their jobs.
We hope that this post proves immensely helpful to you and your organization. In this article we have featured Why Large number of files on Hadoop is a problem and how to fix it? We believe you will implement same good practices at your organization as well.
If you liked this Why Large number of files on Hadoop is a problem and how to fix it? article, then do share it with your colleagues and friends. We would love to hear your success stories in the comments section below.
[…] Why Large number of files on Hadoop is a problem and how to fix it? […]
[…] Why Large number of files on Hadoop is a problem and how to fix it? – This is highly recommended for anyone working on Hadoop or looking to work on it in future. […]